前回まで何回かに分けてフリーランスサイト、クラウドワークスとランサーズをスクレイピングするプログラムについて記事を書きました。

今回は、ただスクレイピングを行うのではなく、スプレッドシートと GAS(Google Apps Script)、Google Cloud Platforma(GCP)のCloud Functionsを利用することで、毎日定時に実行させたり、一定間隔で実行できるようにする、実用的なプログラム(システムとも言えますかね)の構築についてまとめました。現在、私も利用しておりますが、今のところ特にエラーもなくしっかり実行されています。
プログラムを学び始めて少し経ったところ、私はスクレイピングのプログラムは書けるようになったけれど、自動実行させたり、見やすいフォーマットに自動で落とし込んでいるといったような応用の仕方がさっぱりわからない、という状態でした。この記事は、私と同じようなことを考えられている方の参考になればとの思いで書かせて頂きました。
なお、Google Cloud PlatformのCloud Functionsの使い方について以前記事にしていますので、そちらも参考にしてい頂ければと思います。

一人でも多くの方の参考になれば幸いです。
1. プログラムのアーキテクチャと諸環境等
今回のプロググラムのアーキテクチャ(全体の構成)や前提条件についてです。
1-1. アーキテクチャ(システム構造)
今回のプログラムのアーキテクチャは以下の図のようになります。
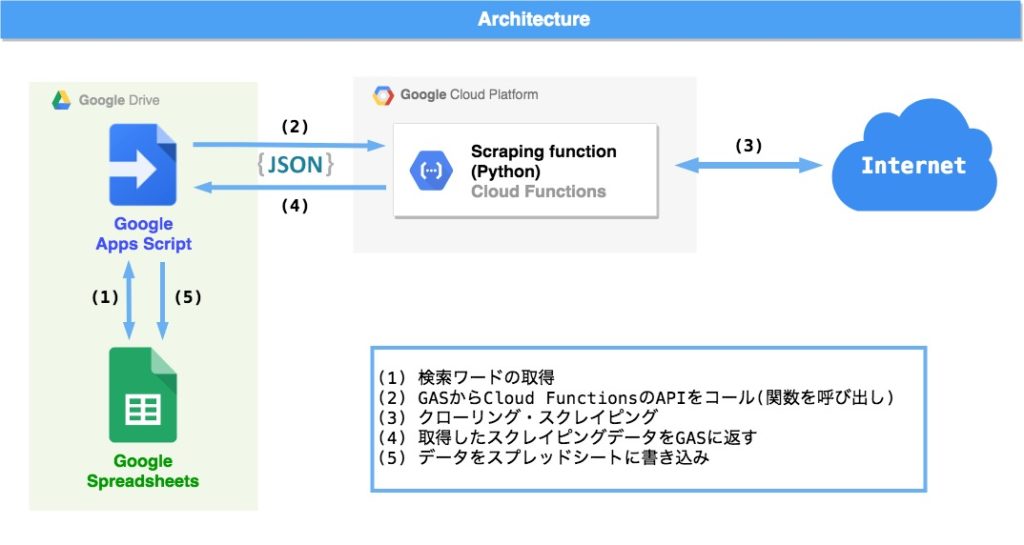
Google Apps Script(GAS)を起点にスプレッドシートから検索ワードを取得し(1)、事前にCloud FunctionsにデプロイしておいたScrapingプログラムを呼び出す(2)ことでスクレイピング(3)を実行します。そしてスクレイピングプログラムから返ってきたスクレイピングデータ(4)をスプレッドシートに書き込む(5)という流れです。起点となるGASにトリガー設定をしておくことで決めた間隔で自動で実行しておくことができます。
1-2. 前提条件とポイント
このプログラムの前提条件とポイントは以下になります。
- 前提条件
- スクレイピング先は以前の記事とリンクさせるため、ランサーズとクラウドワークス
- Cloud Functions上のスクレイピングプログラムPython(3.7)を利用
- トリガーはHTTP
- スクレイピングはrequestとBeautifulSoupモジュールを利用し、seleniumは利用せず(JavaScritp対応が必要なサイトは想定せず)
- スプレッドシートへのスクレイピングデータの書き込みは、シートを上書きする方式で行う
- ポイント
- 検索ワードはスプレッドシートで指定できる
- スプレッドシートに保存する上で行数を取得データの行数を揃える必要があるため、ランサーズ側のリストの要素数をクラウドワークスと同じ9つに調整
- GASとCloud FunctionsのPythonプログラムはデータ形式をJsonでやりとり
1-3. ファイル構成
アーキテクチャに沿ったファイル構成は次のようになります。
・Google Apps Script(GAS) └──func.gs ・スプレッドシート(シート構成) ├── search_words(検索ワードを指定するシート) └── jobs(スクレイピングデータを書き込むシート) ・Cloud Functions(Python) ├── config │ └── config.py ├── crowdworks.py ├── functions.py ├── lancers.py ├── main.py └── requirements.txt
2. プログラム
次にプログラムについて紹介していきます。
2-1. Google Apps Script(GAS)のプログラム
まずはこのプログラムの根幹となるGASのプログラムからです。func.gsファイルのみを利用します。
・GASのプログラムの流れ
GASのプログラム構成は次のようになります。
1. シートの値をクリアし、実行開始時間をA1セルに書き込み 2. "search_words"シートから検索ワードを取得 3. Cloud Functionsにデプロイした関数を呼び出し 4. 返ってきた値をスプレッドシートに書き込み
・GASのプログラム
function myFunction() {
ss = SpreadsheetApp.getActiveSpreadsheet()
// 1. シートの値のクリアと実行時間の入力
sheet = ss.getSheetByName('jobs');
sheet.clear();
range = sheet.getRange(1,1);
var date = new Date();
// 実行時間の入力
range.setValue(Utilities.formatDate( date, 'Asia/Tokyo', 'yyyy年MM月dd日 HH時mm分'));
// 2. search_wordsシートからsearch_wordsの回収
sheet = ss.getSheetByName('search_words')
var range = sheet.getRange(1, 2, 1, sheet.getLastColumn()-1)
var values = range.getValues()
// 3. Cloud Functionsにデプロイした関数を呼び出し
* POSTするJsonデータを生成
data = {'search_words': values[0]}
var options = {
'methods': 'post',
'contentType': 'application/json',
'payload' : JSON.stringify(data)
}
// Cloud Functionsの対象関数のURLを呼び出し
var url = PropertiesService.getScriptProperties().getProperty('cloudFunctionsUrl');
resJson = UrlFetchApp.fetch(url, options=options);
// 4. 返ってきた値をスプレッドシートに書き込み
res = JSON.parse(resJson);
resArray = res['result']
sheet = ss.getSheetByName('jobs')
for (var i=0, len=resArray.length; i < len; i++) {
var array = resArray[i];
var keys = Object.keys(array);
// Object.values()が使えないためmap関数を利用
var vals = keys.map(function(x){
return array[x]
});
range = sheet.getRange(i+2,1,1, 9);
range.setValues([vals])
};
}・GASのプログラムのポイントと注意点
GASのプログラムのポイントと注意点は下記になります。
- ポイント
- スクレイピングデータはプログラムの実行の都度、シートに上書きしていくため、毎回実行当初にシートの値をクリアする
- 実行時間をA1セルに記載
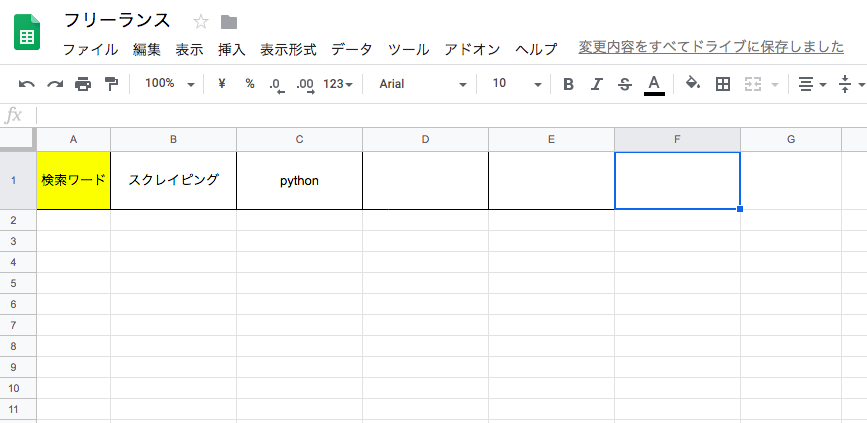
- “search_words”シートは横方向に記載していき、幾つでも設定できる(シートイメージは下記に貼り付け)
- Cloud FunctionsのURLは「プロジェクトのプロパティ」で管理
- Cloud Functionsの関数とはJsonデータでやりとり
- Object.valuesメソッドが使えないため、map関数を利用(アロー関数も使用不可)
- 注意点
- GASのプログラム実行時間は6分以内に抑える必要がある。また1日の総実行時間は1時間以内になる
- GASではObject.valuesメソッドが使えないため、map関数を利用
ちなみに今回、Cloud Functionsでスクレイピングを実行した時の格納方法は辞書を要素とするリストになります(この形->[{},{},{},…])。これはCSVへの出力やプログラムの管理上は辞書型の方が対応しやすいためですが、GASではリスト型を要素とするリスト(この形->[[],[],[],…])にした方がObject.valuesメソッドの問題はおろか書き込み用のfor文さえ不要となり、プログラムの可読性が高まり、また実行速度も上がると思われます。
上記で言及したシートイメージは下記になります。
2-2. Cloud Functions(Python3.7)
続いてCloud Functionsにデプロイしたスクレイピングプログラムです。Cloud Functionsの使い方は共に冒頭で紹介した記事を参照して頂ければと思います。スクレイピングプログラムの基本的なプログラム構造等についても冒頭の記事を参照して頂きたいと思います。ここでは、プログラム内容とポイントについてまとめます。
・スクレイピングのプログラム
それぞれのファイルのプログラムについて記載します。
config/config.py(設定ファイル)
# ドメイン
cw_domain = "https://crowdworks.jp"
la_domain = "https://www.lancers.jp/"
# デフォルトのクロール間隔
defalt_crawl_delay = 1
# ユーザーエージェント
user_agent = "Crawler/1.0.0"
# 除外するサプライヤー(ユーザー名で可)
cw_except_users = []
la_except_users = []
main.py
import csv
import json
import os
import time
# from search_words import search_words
from crowdworks import crowdworks
from lancers import lancers
def execute(req):
req_json = req.get_json(force=True)
search_words = req_json['search_words']
#search_words = req['search_words']
result = []
for func in [crowdworks, lancers]:
result += func(search_words)
return json.dumps({'result': result}) # [{},{},{},,,]crowdworks.py
import re
import time
from bs4 import BeautifulSoup as bs
import requests
from config import config
from functions import parse_robots
# クラウドワークスのスクレイピングの実行プログラム
def crowdworks(search_words):
print("Start scraping for CrowdWorks...")
# 1) robots.txtの確認
domain = config.cw_domain
robot_parser = parse_robots(domain)
crawl_delay = robot_parser.crawl_delay("*")
if not crawl_delay:
crawl_delay = config.defalt_crawl_delay
# ヘッダー設定
result = [{"service": "検索サービス", "word": "検索ワード", "id": "ID", "job_title": "案件名", "url": "URL",
"fee_type": "報酬体系", "fee": "報酬", "start": "掲載日", "end": "募集終了日"}]
# 2) 検索ワードごとにクローリングとスクレイピング
for word in search_words:
print("Start searching for '{}' in CrowdWorks...".format(word))
# クロール間隔の設定
time.sleep(crawl_delay)
# クローリングの実行
html = crawling(word, robot_parser)
# クロールできなかった場合(html=はNone)
if not html:
result.append({"service": "CrowWorks", "word": word, "id": "",
"job_title": '「{}」に該当する案件はありませんでした。'.format(word), "url": "",
"fee_type": "", "fee": "", "start": "", "end": ""})
continue
# スクレイピング
result += scraping(html, word)
return result
# クローリングするプログラム
def crawling(word, robot_parser):
headers = {'User-Agent': config.user_agent, "Accept-Language": "ja,en-US;q=0.9,en;q=0.8"}
search_url = "https://crowdworks.jp/public/jobs/search?search%5Bkeywords%5D={}&keep_search_criteria=false&" \
"order=new&hide_expired=true".format(word)
# 1)robots.txtのチェック
if not robot_parser.can_fetch('*', search_url): # falseの場合
return None
res = requests.get(search_url, headers=headers)
# 2)ステータスコードチェック
if str(res.status_code) != "200":
return None
return res.text
# スクレイピングするプログラム
def scraping(html, word):
result = []
soup = bs(html, 'lxml')
# 1) 検索結果が存在しない場合
if soup.find_all('div', class_="nodata"):
result.append({"service": "CrowdWorks", "word": word, "id": "",
"job_title": '「{}」に該当する案件はありませんでした。'.format(word), "url": "",
"fee_type": "", "fee": "", "start": "", "end": ""})
return result
# 2) 各要素の検索
num = 0
for elem in soup.select('.search_results .jobs_lists > li'):
# 2-1) ユーザーチェック
user = elem.find('span', class_='user-name').a.text
if user in config.cw_except_users:
print("Out of Supplier : {}".format(user))
continue
# 2-2) 該当する案件情報の取得
num += 1
job_title = elem.find('h3', class_="item_title").a.text # ジョブタイトル
job_url = config.cw_domain + elem.find('h3', class_="item_title").a['href']
fee_type = elem.find(class_="payment").find(class_="payment_label").text
fee = ''.join(elem.find(class_="payment").find(class_="amount").text.split())
start = elem.find(class_="post_date").span.next_sibling.strip()
end = re.findall(r'.*((.*)まで)', elem.find('span', class_="absolute_date").text)[0]
result.append({"service": "CrowdWorks", "word": word, "id": num, "job_title": job_title, "url": job_url,
"fee_type": fee_type, "fee": fee, "start": start, "end": end})
print('id {}'.format(num))
if not result:
result.append({"service": "CrowdWorks", "word": word, "id": "",
"job_title": '「{}」に該当する案件はありませんでした。'.format(word), "url": "",
"fee_type": "", "fee": "", "start": "", "end": ""})
return resultlancers.py
import re
import time
from bs4 import BeautifulSoup as bs
import requests
from config import config
from functions import parse_robots
# ランサーズのスクレイピング実行プログラム
def lancers(search_words):
print("Start scraping for Lancers...")
# 1) robots.txtの確認
domain = config.cw_domain
robot_parser = parse_robots(domain)
crawl_delay = robot_parser.crawl_delay("*")
if not crawl_delay:
crawl_delay = config.defalt_crawl_delay
# 取得するスクレイピングデータ(最後の空白要素はクラウドワークスの要素数と合わせるため)
result = [{"service": "検索サービス", "word": "検索ワード", "id": "ID", "job_title": "案件名", "url": "URL",
"job_type": "報酬体型", 'fee': '報酬', 'remaining_period': "残期間", "": ""}]
# 2) 検索ワードごとにクローリングとスクレイピング
for word in search_words:
print("Start searching for '{}' in Lancers...".format(word))
# クロール間隔の調整
time.sleep(crawl_delay)
# クローリングの実行
html = la_crawling(word, robot_parser)
# クロールできなかった場合(html=はNone)
if not html:
result.append({"service": "CrowWorks", "word": word, "id": "",
"job_title": '「{}」に該当する案件はありませんでした。'.format(word), "url": "", "job_type": "",
"fee": "", "remaining_period": "", "": ""})
continue
# スクレイピング
result += la_scraping(html, word)
return result
# クローリング
def la_crawling(word, robot_parser):
headers = {'User-Agent': config.user_agent, "Accept-Language": "ja,en-US;q=0.9,en;q=0.8"}
search_url = "https://www.lancers.jp/work/search?keyword={}&open=1&sort=started&work_rank%5B%5D=0&" \
"work_rank%5B%5D=1&work_rank%5B%5D=2&work_rank%5B%5D=3".format(word)
# 1)robots.txtのチェック
if not robot_parser.can_fetch('*', search_url): # falseの場合
return None
res = requests.get(search_url, headers=headers)
# 2)ステータスコードチェック
if str(res.status_code) != "200":
return None
return res.text
# スクレイピング
def la_scraping(html, word):
result = []
soup = bs(html, 'lxml')
# 1) 検索結果が存在しない場合
if soup.find_all('div', class_="p-search__empty"):
result.append({"service": "Lancers", "word": word, "id": "",
"job_title": '「{}」に該当する案件はありませんでした。'.format(word), "url": "", "job_type": "",
"fee": "", "remaining_period": "", "": ""})
return result
# 2) 各要素の検索
num = 0
for elem in soup.select(".c-media-list.c-media-list--forClient > div"):
# 2-1) ユーザーチェック -> 該当する場合飛ばす
user = user_info(elem.select('.c-avatar__note'))
if user in config.la_except_users:
print("Out of Supplier : {}".format(user))
continue
# 2-2) 該当する案件情報の取得
num += 1
job_title = get_title(elem)
job_url = get_job_url(elem)
job_type = elem.find(class_="c-badge__text").text
fee = ''.join(elem.find(class_="c-media__job-price").text.split())
remaining_period = get_period(elem)
result.append({"service": "Lancers", "word": word, "id": num, "job_title": job_title, "url": job_url,
"job_type": job_type, "fee": fee, "remaining_period": remaining_period, "": ""})
print('id {}'.format(num))
if not result:
result.append({"service": "Lancers", "word": word, "id": "",
"job_title": '「{}」に該当する案件はありませんでした。'.format(word), "url": "", "job_type": "",
"fee": "", "remaining_period": "", "": ""})
return result
# ユーザー情報を抽出する関数
def user_info(tag):
if not tag:
user = None
else:
user = tag[0].text
return user
# ジョブタイトルを求める関数
def get_title(elem):
tags = elem.find_all(class_="c-media__job-tags")
if tags:
tags_text = tags[0].text
title_elem = elem.find_all(class_="c-media__title-inner")[0].text.split()
title_list = [i for i in title_elem if i not in tags_text]
else:
title_list = elem.find_all(class_="c-media__title-inner")[0].text.split()
job_title = ' '.join(title_list)
return job_title
# ジョブURLを抽出する関数
def get_job_url(elem):
url = elem.find(class_="c-media__title")['href']
if re.search(r'https://', url):
job_url = url
else:
job_url = config.la_domain + url
return job_url
# 残期間を抽出する関数
def get_period(elem):
period_tag = elem.find(class_="c-media__job-time__remaining")
if period_tag:
remaining_period = period_tag.text
else:
remaining_period = None
return remaining_periodfunctions.py
import os
import urllib.robotparser
# robot.txtをパースする
def parse_robots(domain):
robots_url = os.path.join(domain, 'robots.txt')
rp = urllib.robotparser.RobotFileParser()
rp.set_url(robots_url)
rp.read()
return rprequirements.txt
beautifulsoup4==4.7.1 bs4==0.0.1 certifi==2019.6.16 chardet==3.0.4 idna==2.8 lxml==4.3.4 requests==2.22.0 soupsieve==1.9.2 urllib3==1.25.3
・スクレイピングプログラムのポイント
- ポイント
- スクレイピング時にはユーザーエージェントを設定
- ランサーズのスクレイピングプログラムではクラウドワークスと辞書の要素数と同じにするために空文字列のkey-valueを追加
2-3. プログラムの実行
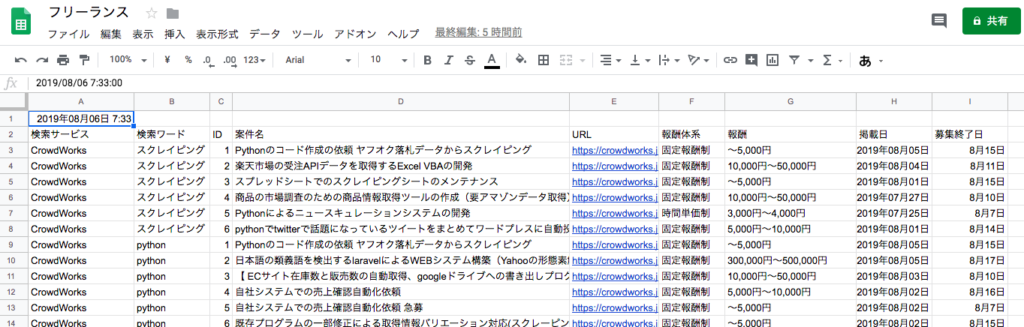
スクレイピングプログラムをGoogle Cloud PlatformのCloud Functionsにデプロイし、GASのfunc.gsを実行すると以下のようにスプレッドシートにスクレイピングデータが保存されると思います(Cloud Functionsへのプログラムの設置方法は冒頭で紹介した記事を参考にして頂ければと思います)。あとはGASにトリガー設定すれば決まった時間にプログラムが実行されます。
プログラム実行後のスプレッドシートのイメージは下記になります。
3. 最後に
以上が「スプレッドシート + GAS(Google Apps Script) + Cloud Functions で自動実行するスクレイピングシステム」についてです。1日1回実行する程度ではGoogle Cloud Platformで課金されることはまずないと思います(実際に私は今のところ、料金は発生していません)。クラウドの世界の競争が激しくなった分、個人でちょっとしたプログラムを自動で実行させるのは、非常に簡単で低コストになりました。アプリを開発して収益化を目指すのも面白いですが、このようなちょっとしたお手軽ツールを作るのまたプログラミング学習の醍醐味と面白さだなと今回、改めて感じました。
最後までお読み頂き、ありがとうございました。この記事が参考になれば幸いです。